賽博圍棋 AI 指南 - 配置 Katago 與 Leela-Zero
1 前言
AlphaGo(「Go」為日文「碁」字發音轉寫,是圍棋的西方名稱),直譯為阿爾法圍棋,亦被音譯為阿爾法狗,是於 2014 年開始由英國倫敦 Google DeepMind 開發的人工智慧圍棋軟體,以及對應的電影紀錄片《 AlphaGo 世紀對決》。
專業術語上來說,AlphaGo 的做法是使用了蒙地卡羅樹搜尋與兩個深度神經網路相結合的方法,一個是以藉助估值網路(value network)來評估大量的選點,一個是藉助走棋網路(policy network)來選擇落子,並使用強化學習進一步改善它。在這種設計下,電腦可以結合樹狀圖的長遠推斷,又可像人類的大腦一樣自發學習進行直覺訓練,以提高下棋實力。

2016 年 3 月 9 、10 和 12 日的三局對戰均為 AlphaGo 獲勝,而 13 日的對戰則為李世乭獲勝,15 日的最終局則又是 AlphaGo 獲勝。因此對弈結果為 AlphaGo 4:1 戰勝了李世乭。這次比賽在網路上引發了人們對此次比賽和人工智慧的廣泛討論。

AlphaGo 在 2017 年 5 月 23、25 和 27日這三天,柯潔與 AlphaGo 下三番棋,用時為每方 3 小時,5 次 1 分鐘讀秒。此外在 5 月 26 日,時越、羋昱廷、唐韋星、陳耀燁和周睿羊 5 人將進行團隊賽,他們將聯合與 AlphaGo 對弈,用時為每方 2 小時 30 分鐘,3 次 1 分鐘讀秒。最終,AlphaGo 以 3:0 戰勝柯潔。

同日下午,中國的五名九段棋手組團對抗 AlphaGo。他們分別是時越、羋昱廷、唐韋星、陳耀燁和周睿羊。其結局為 AlphaGo 執白盤中獲勝。
此外,AlphaGo 團隊也在 Nature 上公開發佈了相關的論文
Mastering the game of Go with deep neural networks and tree search
Mastering the game of Go without human knowledge
根據論文中展示的相關運行原理,Github 上許多大神也相繼開發出了更多的圍棋 AI。
更多關於 AlphaGo 的信息可以參考 Wikipedia 和官方網站的介紹。
2 配置 Nvidia 相關環境
-
必須安裝 Nvidia Cublas
-
如果擁有 Nvidia 10 系以上的顯卡可以使用 cuda 版本 (舊的 Katago v1.13.0及以下),在使用前還需安裝 Nvidia cuDNN, 對應的版本是 cuDNN v7.6.5 (November 5th, 2019), for CUDA 9.2
-
如果使用了 TensorRT 的版本 (新的Katago v1.13.1及以上),則需要安裝 Nvidia TensorRT
3 配置 Katago
KataGo 是新的開源圍棋AI,支持所有貼目、所有路數的矩形棋盤(甚至包括長方形),棋風不退讓,支持中國規則和日本規則(數目規則)。下一個版本,KataGo 還將支持日本規則中的特例、中國古棋規則(還棋頭)、非矩形的不規則棋盤 和 Button Go!
3.1 下載 Katago
前往 https://github.com/lightvector/KataGo/releases 下載執行文件
其他顯卡可以使用 opencl 版本
3.1.1 配置 Katago
先下載和配置權重文件,權重文件包含目前 AI 的訓練勝率統計結果,AlphaGo Zero 采集了目前各類圍棋專業比賽的棋盤數據,如果使用家用游戲顯卡(例如 Nvidia GTX 1080 Ti)進行 AI 訓練,大概需要 1700 年的時間,為了節約時間可以下載網絡上已經訓練完成的權重文件,當然也可以自己拿相關棋盤數據進行訓練。
前往 Katago 官網的 Network 中下載權重壓縮包,可以選擇純文本或二進制包
https://katagotraining.org/networks/
可以下載 Latest network 和 Strongest confidently-rated network 版本
3.1.2 配置 Katago 權重
進入終端執行
katago.exe genconfig -model kata1-b18c384nbt-s8100581632-d3817849642.bin.gz -output gtp_custom.cfg
其中 kata1-b18c384nbt-s8100581632-d3817849642.bin.gz 為剛剛下載的權重文件,如果是純文本文件,則為 kata1-b18c384nbt-s8100581632-d3817849642.txt
之後配置程序會詢問圍棋進行規則和相關參數設置
RULES
What rules should KataGo use by default for play and analysis?
(chinese, japanese, korean, tromp-taylor, aga, chinese-ogs, new-zealand, bga, stone-scoring, aga-button):
這是問默認的圍棋規則是什麼,貌似你甚至可以選擇還棋頭,感興趣的同學可以自行了解,我們這裡就選中國規則(應氏規則,貼7.5),
輸入:chinese,然後回車
SEARCH LIMITS
When playing games, KataGo will always obey the time controls given by the GUI/tournament/match/online server.
But you can specify an additional limit to make KataGo move much faster. This does NOT affect analysis/review,
only affects playing games. Add a limit? (y/n) (default n):
這是問是否需要對讀秒之類的時間規則加個額外限制,我們這裡選不用
輸入:n,然後回車
接著看到提示
NOTE: No limits configured for KataGo. KataGo will obey time controls provided by the GUI or server or match script
but if they don't specify any, when playing games KataGo may think forever without moving. (press enter to continue)
繼續回車。
When playing games, KataGo can optionally ponder during the opponent's turn. This gives faster/stronger play
in real games but should NOT be enabled if you are running tests with fixed limits (pondering may exceed those
limits), or to avoid stealing the opponent's compute time when testing two bots on the same machine.
Enable pondering? (y/n, default n):
這是問是否允許在對手讀秒的時候思考,然後這麼做要注意什麼,默認是否
所以直接回車
GPUS AND RAM
Finding available GPU-like devices...
Found OpenCL Device 0: GeForce GTX 1060 (NVIDIA Corporation) (score 11000102)
Specify devices/GPUs to use (for example "0,1,2" to use devices 0, 1, and 2). Leave blank for a default SINGLE-GPU config:
0
根據硬件配置,每個人看到的不一樣,這是問要使用哪個計算核心,每個選項最後面都有一個數字,選那個數字最大的就好。
我只有一張獨立顯卡,所以我直接回車。如果有多個計算核心,請輸入相應的數字後回車即可
By default, KataGo will cache up to about 3GB of positions in memory (RAM), in addition to
whatever the current search is using. Specify a different max in GB or leave blank for default:
這是在問 Katago 運行時的內存上限設置為多少。上限而已,那我們直接拉滿就好
建議電腦經常卡的輸入: 1
建議偶爾會卡的輸入: 2
建議直接回車
PERFORMANCE TUNING
Specify number of visits to use test/tune performance with, leave blank for default based on GPU speed.
Use large number for more accurate results, small if your GPU is old and this is taking forever:
直接回車,最後會刷出來一堆提示信息
2023-07-10 21:54:01+0800: Loading model and initializing benchmark...
Running quick initial benchmark at 16 threads!
2023-07-10 21:54:01+0800: nnRandSeed0 = 967512229685620723
2023-07-10 21:54:01+0800: After dedups: nnModelFile0 = kata1-b18c384nbt-s8100581632-d3817849642.bin.gz useFP16 auto useNHWC auto
2023-07-10 21:54:03+0800: Found OpenCL Platform 0: NVIDIA CUDA (NVIDIA Corporation) (OpenCL 1.2 CUDA 11.2.109)
2023-07-10 21:54:03+0800: Found 1 device(s) on platform 0 with type CPU or GPU or Accelerator
2023-07-10 21:54:03+0800: Found OpenCL Device 0: GeForce GTX 1060 (NVIDIA Corporation) (score 11000102)
2023-07-10 21:54:03+0800: Creating context for OpenCL Platform: NVIDIA CUDA (NVIDIA Corporation) (OpenCL 1.2 CUDA 11.2.109)
2023-07-10 21:54:03+0800: Using OpenCL Device 0: GeForce GTX 1060 (NVIDIA Corporation) OpenCL 1.2 CUDA (Extensions: cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_fp64 cl_khr_byte_addressable_store cl_khr_icd cl_khr_gl_sharing cl_nv_compiler_options cl_nv_device_attribute_query cl_nv_pragma_unroll cl_nv_d3d10_sharing cl_khr_d3d10_sharing cl_nv_d3d11_sharing cl_nv_copy_opts cl_nv_create_buffer cl_khr_int64_base_atomics cl_khr_int64_extended_atomics cl_khr_device_uuid)
2023-07-10 21:54:03+0800: No existing tuning parameters found or parseable or valid at: D:\AI\katago/KataGoData/opencltuning/tune8_gpuGeForceGTX1060_x19_y19_c256_mv10.txt
2023-07-10 21:54:03+0800: Performing autotuning
2023-07-10 21:54:03+0800: *** On some systems, this may take several minutes, please be patient ***
2023-07-10 21:54:03+0800: Found OpenCL Platform 0: NVIDIA CUDA (NVIDIA Corporation) (OpenCL 1.2 CUDA 11.2.109)
2023-07-10 21:54:03+0800: Found 1 device(s) on platform 0 with type CPU or GPU or Accelerator
2023-07-10 21:54:03+0800: Found OpenCL Device 0: GeForce GTX 1060 (NVIDIA Corporation) (score 11000102)
2023-07-10 21:54:03+0800: Creating context for OpenCL Platform: NVIDIA CUDA (NVIDIA Corporation) (OpenCL 1.2 CUDA 11.2.109)
2023-07-10 21:54:03+0800: Using OpenCL Device 0: GeForce GTX 1060 (NVIDIA Corporation) OpenCL 1.2 CUDA (Extensions: cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_fp64 cl_khr_byte_addressable_store cl_khr_icd cl_khr_gl_sharing cl_nv_compiler_options cl_nv_device_attribute_query cl_nv_pragma_unroll cl_nv_d3d10_sharing cl_khr_d3d10_sharing cl_nv_d3d11_sharing cl_nv_copy_opts cl_nv_create_buffer cl_khr_int64_base_atomics cl_khr_int64_extended_atomics cl_khr_device_uuid)
Setting winograd3x3TileSize = 4
------------------------------------------------------
Tuning xGemmDirect for 1x1 convolutions and matrix mult
Testing 56 different configs
Tuning 0/56 (reference) Calls/sec 792.653 L2Error 0 WGD=8 MDIMCD=1 NDIMCD=1 MDIMAD=1 NDIMBD=1 KWID=1 VWMD=1 VWND=1 PADA=1 PADB=1
Tuning 2/56 Calls/sec 6680.96 L2Error 0 WGD=8 MDIMCD=8 NDIMCD=8 MDIMAD=8 NDIMBD=8 KWID=1 VWMD=1 VWND=1 PADA=1 PADB=1
Tuning 3/56 Calls/sec 13272 L2Error 0 WGD=16 MDIMCD=8 NDIMCD=8 MDIMAD=8 NDIMBD=8 KWID=1 VWMD=1 VWND=1 PADA=1 PADB=1
Tuning 4/56 Calls/sec 22568.9 L2Error 0 WGD=32 MDIMCD=8 NDIMCD=8 MDIMAD=16 NDIMBD=8 KWID=2 VWMD=2 VWND=2 PADA=1 PADB=1
Tuning 6/56 Calls/sec 22606.4 L2Error 0 WGD=32 MDIMCD=8 NDIMCD=8 MDIMAD=8 NDIMBD=16 KWID=2 VWMD=2 VWND=2 PADA=1 PADB=1
Tuning 8/56 Calls/sec 23462 L2Error 0 WGD=32 MDIMCD=8 NDIMCD=8 MDIMAD=16 NDIMBD=8 KWID=2 VWMD=2 VWND=4 PADA=1 PADB=1
Tuning 11/56 Calls/sec 23972.3 L2Error 0 WGD=32 MDIMCD=8 NDIMCD=8 MDIMAD=16 NDIMBD=16 KWID=2 VWMD=2 VWND=2 PADA=1 PADB=1
Tuning 40/56 ...
------------------------------------------------------
Tuning xGemm for convolutions
Testing 70 different configs
Tuning 0/70 (reference) Calls/sec 418.777 L2Error 0 MWG=8 NWG=8 KWG=8 MDIMC=1 NDIMC=1 MDIMA=1 NDIMB=1 KWI=1 VWM=1 VWN=1 STRM=0 STRN=0 SA=0 SB=0
Tuning 2/70 Calls/sec 1457.92 L2Error 0 MWG=8 NWG=8 KWG=8 MDIMC=8 NDIMC=8 MDIMA=8 NDIMB=8 KWI=1 VWM=1 VWN=1 STRM=0 STRN=0 SA=0 SB=0
Tuning 3/70 Calls/sec 2508.42 L2Error 0 MWG=16 NWG=16 KWG=16 MDIMC=8 NDIMC=8 MDIMA=8 NDIMB=8 KWI=1 VWM=1 VWN=1 STRM=0 STRN=0 SA=0 SB=0
Tuning 4/70 Calls/sec 3688.01 L2Error 0 MWG=32 NWG=32 KWG=32 MDIMC=16 NDIMC=8 MDIMA=16 NDIMB=8 KWI=2 VWM=2 VWN=2 STRM=0 STRN=0 SA=0 SB=0
Tuning 5/70 Calls/sec 10323 L2Error 0 MWG=32 NWG=32 KWG=16 MDIMC=8 NDIMC=8 MDIMA=8 NDIMB=8 KWI=2 VWM=2 VWN=2 STRM=0 STRN=0 SA=1 SB=1
Tuning 6/70 Calls/sec 10866.7 L2Error 0 MWG=64 NWG=64 KWG=16 MDIMC=8 NDIMC=8 MDIMA=8 NDIMB=8 KWI=2 VWM=4 VWN=4 STRM=0 STRN=0 SA=1 SB=1
Tuning 12/70 Calls/sec 11658.7 L2Error 0 MWG=64 NWG=64 KWG=32 MDIMC=16 NDIMC=8 MDIMA=16 NDIMB=8 KWI=2 VWM=4 VWN=4 STRM=0 STRN=0 SA=1 SB=1
Tuning 40/70 ...
Tuning 60/70 ...
Tuning 62/70 Calls/sec 11666.6 L2Error 0 MWG=32 NWG=32 KWG=16 MDIMC=8 NDIMC=8 MDIMA=8 NDIMB=8 KWI=2 VWM=4 VWN=4 STRM=0 STRN=0 SA=1 SB=1
------------------------------------------------------
Tuning hGemmWmma for convolutions
Testing 146 different configs
FP16 tensor core tuning failed, assuming no FP16 tensor core support
------------------------------------------------------
Tuning xGemm for convolutions - trying with FP16 storage
Testing 70 different configs
Tuning 0/70 (reference) Calls/sec 395.485 L2Error 0 MWG=8 NWG=8 KWG=8 MDIMC=1 NDIMC=1 MDIMA=1 NDIMB=1 KWI=1 VWM=1 VWN=1 STRM=0 STRN=0 SA=0 SB=0
Tuning 1/70 Calls/sec 11471.6 L2Error 0 MWG=32 NWG=32 KWG=16 MDIMC=8 NDIMC=8 MDIMA=8 NDIMB=8 KWI=2 VWM=4 VWN=4 STRM=0 STRN=0 SA=1 SB=1
Tuning 4/70 Calls/sec 13676.1 L2Error 0 MWG=64 NWG=64 KWG=16 MDIMC=8 NDIMC=16 MDIMA=8 NDIMB=16 KWI=2 VWM=4 VWN=4 STRM=0 STRN=0 SA=1 SB=1
Tuning 20/70 ...
Tuning 40/70 ...
Tuning 54/70 Calls/sec 13692.4 L2Error 0 MWG=64 NWG=64 KWG=16 MDIMC=16 NDIMC=8 MDIMA=16 NDIMB=8 KWI=2 VWM=4 VWN=4 STRM=0 STRN=0 SA=1 SB=1
FP16 storage not significantly faster, not enabling on its own
------------------------------------------------------
Using FP32 storage!
Using FP32 compute!
------------------------------------------------------
Tuning winograd transform for convolutions
Testing 47 different configs
Tuning 0/47 (reference) Calls/sec 9501.37 L2Error 0 transLocalSize0=1 transLocalSize1=1
Tuning 2/47 Calls/sec 17277.9 L2Error 0 transLocalSize0=1 transLocalSize1=8
Tuning 3/47 Calls/sec 49638.2 L2Error 0 transLocalSize0=4 transLocalSize1=2
Tuning 5/47 Calls/sec 50017.8 L2Error 0 transLocalSize0=4 transLocalSize1=32
Tuning 6/47 Calls/sec 55704.1 L2Error 0 transLocalSize0=32 transLocalSize1=1
Tuning 15/47 Calls/sec 60302.3 L2Error 0 transLocalSize0=16 transLocalSize1=4
Tuning 17/47 Calls/sec 61963 L2Error 0 transLocalSize0=16 transLocalSize1=8
Tuning 40/47 ...
------------------------------------------------------
Tuning winograd untransform for convolutions
Testing 111 different configs
Tuning 0/111 (reference) Calls/sec 13785.4 L2Error 0 untransLocalSize0=1 untransLocalSize1=1 untransLocalSize2=1
Tuning 1/111 Calls/sec 13793.5 L2Error 0 untransLocalSize0=1 untransLocalSize1=1 untransLocalSize2=1
Tuning 2/111 Calls/sec 38954.3 L2Error 0 untransLocalSize0=1 untransLocalSize1=32 untransLocalSize2=1
Tuning 3/111 Calls/sec 40903.1 L2Error 0 untransLocalSize0=2 untransLocalSize1=32 untransLocalSize2=16
Tuning 4/111 Calls/sec 44728.1 L2Error 0 untransLocalSize0=8 untransLocalSize1=4 untransLocalSize2=16
Tuning 10/111 Calls/sec 48208.8 L2Error 0 untransLocalSize0=8 untransLocalSize1=1 untransLocalSize2=4
Tuning 13/111 Calls/sec 49402.8 L2Error 0 untransLocalSize0=8 untransLocalSize1=2 untransLocalSize2=8
Tuning 16/111 Calls/sec 52025.5 L2Error 0 untransLocalSize0=8 untransLocalSize1=1 untransLocalSize2=2
Tuning 40/111 ...
Tuning 60/111 ...
Tuning 63/111 Calls/sec 52354.8 L2Error 0 untransLocalSize0=16 untransLocalSize1=1 untransLocalSize2=2
Tuning 80/111 ...
Tuning 100/111 ...
------------------------------------------------------
Tuning global pooling strides
Testing 73 different configs
Tuning 0/73 (reference) Calls/sec 129696 L2Error 0 XYSTRIDE=1 CHANNELSTRIDE=1 BATCHSTRIDE=1
Tuning 2/73 Calls/sec 243640 L2Error 3.4579e-12 XYSTRIDE=8 CHANNELSTRIDE=2 BATCHSTRIDE=1
Tuning 8/73 Calls/sec 247602 L2Error 3.38951e-12 XYSTRIDE=16 CHANNELSTRIDE=2 BATCHSTRIDE=2
Tuning 13/73 Calls/sec 259166 L2Error 3.38951e-12 XYSTRIDE=16 CHANNELSTRIDE=4 BATCHSTRIDE=2
Tuning 40/73 ...
Tuning 60/73 ...
Done tuning
------------------------------------------------------
2023-07-10 21:54:49+0800: Done tuning, saved results to D:\AI\katago/KataGoData/opencltuning/tune8_gpuGeForceGTX1060_x19_y19_c256_mv10.txt
2023-07-10 21:54:51+0800: OpenCL backend thread 0: Model version 10
2023-07-10 21:54:51+0800: OpenCL backend thread 0: Model name: kata1-b40c256-s5942610176-d1431052518
2023-07-10 21:54:52+0800: OpenCL backend thread 0: FP16Storage false FP16Compute false FP16TensorCores false
numSearchThreads = 16: 3 / 3 positions, visits/s = 259.09 nnEvals/s = 221.89 nnBatches/s = 28.50 avgBatchSize = 7.78 (9.4 secs)
=========================================================================
TUNING NOW
Tuning using 500 visits.
Automatically trying different numbers of threads to home in on the best:
Possible numbers of threads to test: 1, 2, 3, 4, 5, 6, 8, 10, 12, 16, 20, 24, 32,
numSearchThreads = 5: 10 / 10 positions, visits/s = 210.68 nnEvals/s = 183.63 nnBatches/s = 73.99 avgBatchSize = 2.48 (23.9 secs)
numSearchThreads = 12: 10 / 10 positions, visits/s = 235.81 nnEvals/s = 211.49 nnBatches/s = 36.09 avgBatchSize = 5.86 (21.7 secs)
numSearchThreads = 10: 10 / 10 positions, visits/s = 228.77 nnEvals/s = 202.48 nnBatches/s = 41.31 avgBatchSize = 4.90 (22.2 secs)
numSearchThreads = 20: 10 / 10 positions, visits/s = 234.74 nnEvals/s = 216.51 nnBatches/s = 22.52 avgBatchSize = 9.61 (22.1 secs)
numSearchThreads = 8: 10 / 10 positions, visits/s = 230.31 nnEvals/s = 202.28 nnBatches/s = 51.24 avgBatchSize = 3.95 (22.0 secs)
numSearchThreads = 6: 10 / 10 positions, visits/s = 236.61 nnEvals/s = 205.45 nnBatches/s = 69.20 avgBatchSize = 2.97 (21.3 secs)
Ordered summary of results:
numSearchThreads = 5: 10 / 10 positions, visits/s = 210.68 nnEvals/s = 183.63 nnBatches/s = 73.99 avgBatchSize = 2.48 (23.9 secs) (EloDiff baseline)
numSearchThreads = 6: 10 / 10 positions, visits/s = 236.61 nnEvals/s = 205.45 nnBatches/s = 69.20 avgBatchSize = 2.97 (21.3 secs) (EloDiff +38)
numSearchThreads = 8: 10 / 10 positions, visits/s = 230.31 nnEvals/s = 202.28 nnBatches/s = 51.24 avgBatchSize = 3.95 (22.0 secs) (EloDiff +16)
numSearchThreads = 10: 10 / 10 positions, visits/s = 228.77 nnEvals/s = 202.48 nnBatches/s = 41.31 avgBatchSize = 4.90 (22.2 secs) (EloDiff +1)
numSearchThreads = 12: 10 / 10 positions, visits/s = 235.81 nnEvals/s = 211.49 nnBatches/s = 36.09 avgBatchSize = 5.86 (21.7 secs) (EloDiff +1)
numSearchThreads = 20: 10 / 10 positions, visits/s = 234.74 nnEvals/s = 216.51 nnBatches/s = 22.52 avgBatchSize = 9.61 (22.1 secs) (EloDiff -47)
Based on some test data, each speed doubling gains perhaps ~250 Elo by searching deeper.
Based on some test data, each thread costs perhaps 7 Elo if using 800 visits, and 2 Elo if using 5000 visits (by making MCTS worse).
So APPROXIMATELY based on this benchmark, if you intend to do a 5 second search:
numSearchThreads = 5: (baseline)
numSearchThreads = 6: +38 Elo (recommended)
numSearchThreads = 8: +16 Elo
numSearchThreads = 10: +1 Elo
numSearchThreads = 12: +1 Elo
numSearchThreads = 20: -47 Elo
Using 6 numSearchThreads!
=========================================================================
DONE
Writing new config file to gtp_custom.cfg
You should be now able to run KataGo with this config via something like:
katago.exe gtp -model 'kata1-b18c384nbt-s8100581632-d3817849642.bin.gz' -config 'gtp_custom.cfg'
Feel free to look at and edit the above config file further by hand in a txt editor.
For more detailed notes about performance and what options in the config do, see:
https://github.com/lightvector/KataGo/blob/master/cpp/configs/gtp_example.cfg
此時配置文件已經完成,可以進行下一步配置 GUI 棋盤,但建議此終端窗口暫時不要關閉。
3.2 配置適用於 Kotako 的 Sabaki 棋盤
此處介紹 Sabaki 的配置方法,此外還有 Lizzie 可供使用
3.2.1 下載 Sabaki
前往 Sabaki 的 Github 項目頁面下載程序包
https://github.com/SabakiHQ/Sabaki/releases
選擇相應系統的程序包,下載完成后解壓
3.2.2 配置 Sabaki
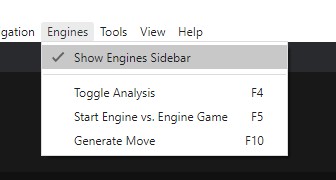
首先勾選 Englines 菜單内的 Show Engines Sidebar
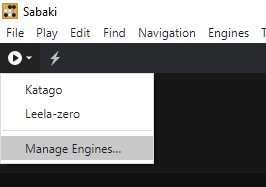
側欄進入 Engine 管理
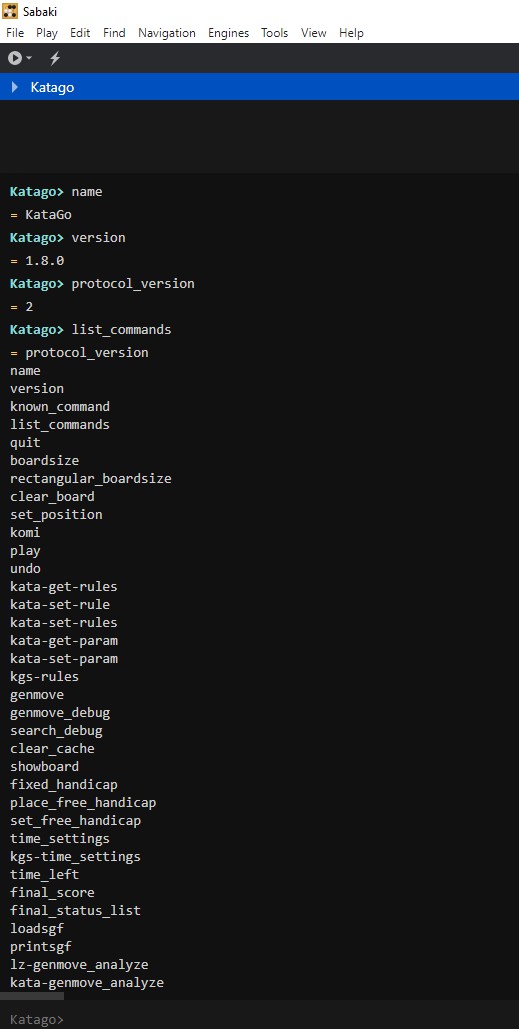
之後設置 Kotago 的路徑和運行參數

我的設置是
gtp -model D:\AI\katago\kata1-b18c384nbt-s8100581632-d3817849642.bin.gz -config D:\AI\katago\gtp_custom.cfg
和
time_settings 10 15 1
在中國規則(應氏規則)中,上面這個意思就是計時 10 分鐘,15 秒每次,超時計 1 點。
之後右下角 Close 退出自動保存,Kotago 就設置完成了
4 配置 Leela-Zero
Leela Zero 是由比利時程式設計師 Gian-Carlo Pascutto 起頭所開發的電腦圍棋軟體,以及相關的運算計畫。
4.1 下載 Leela-Zero 和權重文件
前往 https://github.com/leela-zero/leela-zero/releases 下載執行文件
沒有獨立顯卡可以使用 cpuonly 版本
前往 https://zero.sjeng.org/best-network 下載壓縮文件,之後解壓得到 leelaz-model-swa-16-128000_quantized.txt,將此文件放入 Leela-Zero 主文件夾
4.2 配置適用於 Leela-Zero 的 Sabaki 棋盤
同 2.2.2,進入 Engine 管理,設置 Leela-Zero 的路徑和運行參數

5 選擇棋局對戰雙方和規則設置
Sabaki 右下角進入 info 棋局設置
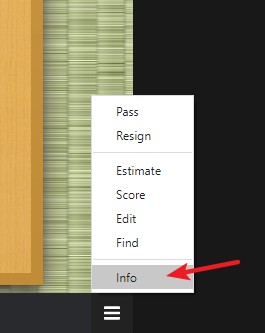
選擇棋局對戰 AI或人類玩家
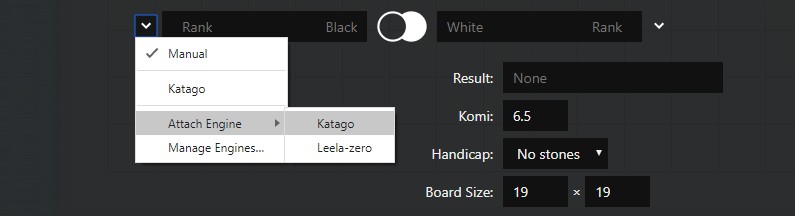
棋局規則設置
Komi:貼目
Handicap:讓子,默認不讓子
Board Size:默認只支持 19X19
之後選擇 OK 設置完成
6 開始對戰
進入 Englines 菜單内的 Start Engine vs. Engine Game
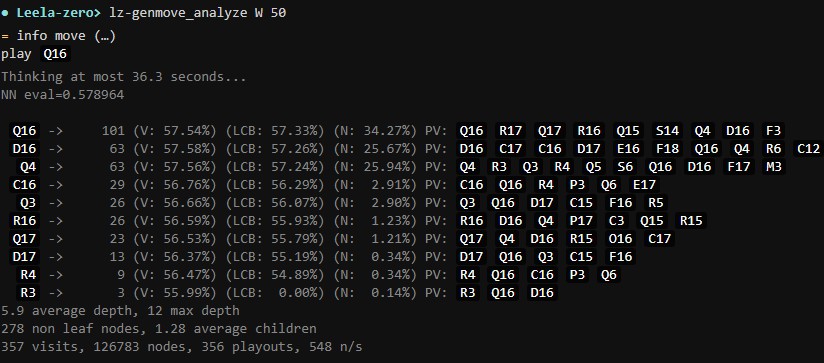
之後就可以進行自動 AI 對戰,Sabaki 也提供了每一步的勝率計算和下子坐標推薦
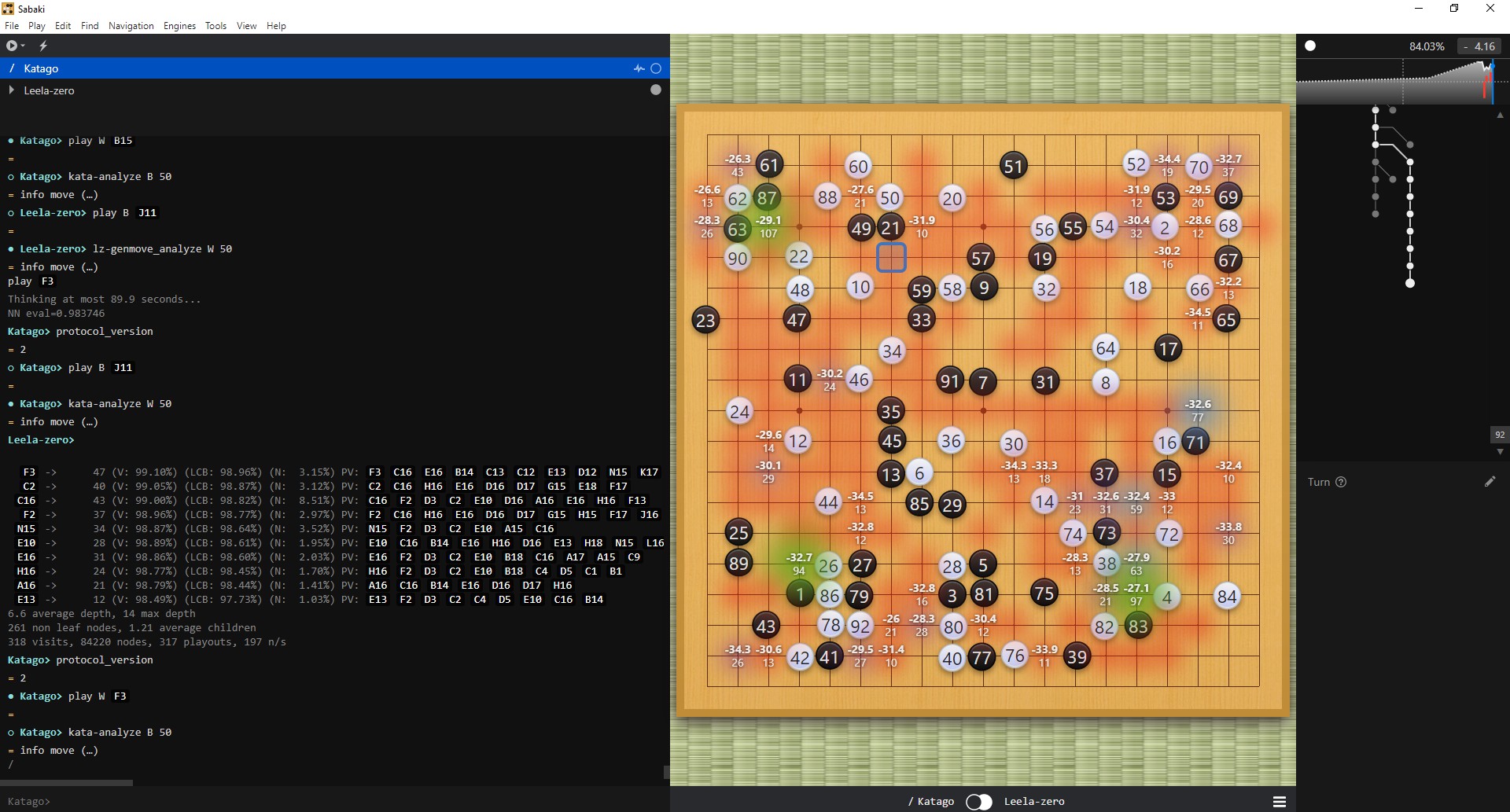
7 懶人包
Sabaki + Katago(支持 OpenCL/CUDA/TensorRT) + Leela Zero 整合包
https://archive.org/details/ai-go.-7z
下載後解壓運行即可